


Artikel
So transformiert Knowledge Engineering die Datenlandschaft in Unternehmen
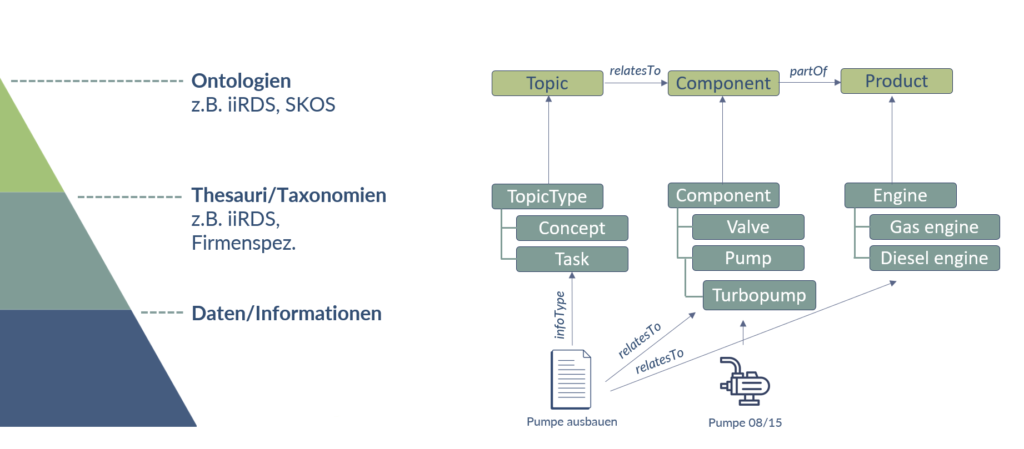
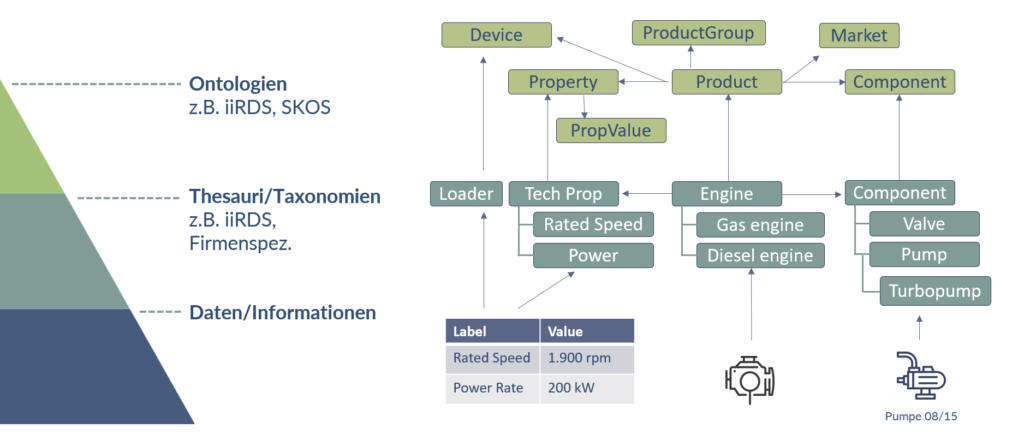
Unternehmen verfügen heute über mehr Daten als je zuvor und damit über enormes Potenzial. Richtig genutzt ermöglichen Daten bessere Entscheidungen, reduzieren blinde Flecken und machen komplexe Zusammenhänge sichtbar.
Artikel
DPP in der Praxis: Wie der digitale Produktpass zum Motor für den Informationshub wird
Damit der digitale Produktpass kein weiterer Datencontainer wird, müssen Unternehmen ihre Informationsstrategie neu denken.
Artikel
Bedeutung von Semantik in der Technischen Kommunikation
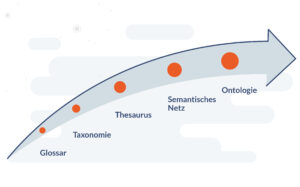
Wie Sie durch Semantik in der technischen Kommunikation und semantisches Wissensmanagement Produktinformationen effizienter und zukunftssicher nutzen.
