18. Februar 2025
Out-of-the-Box-Lösungen für RAG-Systeme (Retrieval Augmented Generation) verbreiten sich immer weiter. Sie versprechen, das Wissen eines Unternehmens aus Dokumenten wie PDFs oder Word-Dateien mithilfe von Large Language Models (LLMs) in Form eines Chats zugänglich zu machen. In diesem Kontext stellt sich unweigerlich die Frage: Können wir nicht ein LLM mit Knowledge Graph verbessern? Welche Rolle spielen Knowledge Graphen in diesem Szenario noch und welchen Mehrwert können sie bieten?
Anders formuliert: Wenn ich alle meine Texte per Chat verfügbar machen kann, warum sollte ich Geld- und Zeitressourcen in die Strukturierung meines Wissens investieren?
Aus Sicht eines Unternehmens, das diese Ressourcen bereits einsetzt, also einen Knowledge Graphen zur Verfügung hat, stellt sich wiederum die Frage, ob ein LLM noch Mehrwert bieten kann. Dies gilt insbesondere, da LLMs ja für ihr Halluzinieren und Falschinformationen bekannt sind.
Strukturierte Daten für das Large Language Model (LLM)
Um Textdateien wie PDFs für einen LLM-getriebenen Chat verfügbar zu machen, müssen die Textdateien in Sinnabschnitte zerlegt (Chunking) und jeder Textteil in Vektoren überführt (Embeddings) und abgespeichert werden (Vektordatenbank). Darauf aufbauend wird bei einer Anfrage an den Chat die Anfrage selbst vektorisiert und anhand mathematisch-geometrischer Funktionen der semantisch naheliegendste Textabschnitt an das LLM zurückgegeben und von diesem zur finalen Antwort umformuliert.
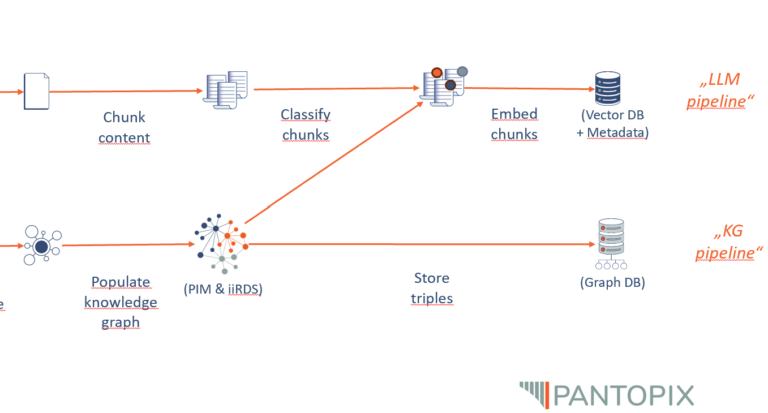
Nicht trivial ist dabei, auf welcher Granularität die Sinnabschnitte zu wählen sind (Dokumente, Kapitel, Seiten, Paragrafen, Sätze) und wie nah Anfrage- und Quellvektor zueinander liegen sollen, um als inhaltlich relevant zu gelten. Methoden, in denen die Textteile mit Metadaten (Thema, Autor, Textform, Position etc.) angereichert werden, welche wiederum in die Embeddings inkludiert werden und somit die Position im semantischen Raum nachschärfen, können hilfreich sein, müssen aber individuell auf die vorhandenen Daten angepasst werden und sind somit nicht Out-of-the-Box verfügbar.
Genau hier liegt die Stärke des Knowledge Graph und die Antwort auf die Frage, wie wir ein LLM mit Knowledge-Graph-Technologie verbessern können. Im Graphen ist der Gesamtkontext einer einzelnen Information von vorneherein mit angelegt und über einfache Abfragen (SPARQL-Queries) in beliebiger Tiefe und Breite zugänglich. Das bedeutet für ein Chat-System, dass nach Themenzuordnung der User-Anfrage die Antwort aus gesichert zum Kontext passenden Informationsbausteinen zusammengefügt werden kann, ohne sich auf die Struktur des semantischen Vektorraums verlassen zu müssen.
Des Weiteren sind die Informationen in einem Knowledge Graphen einfach zugänglich, dynamisch und modular anpassbar, aktuell und kuratiert. Deshalb kann das im Knowledge Graphen codierte Wissen nicht nur zur Kontexterweiterung des LLMs beitragen, sondern auch genutzt werden, um dessen Ausgaben zu validieren. Da syntaktisch betrachtet die Informationen im Knowledge Graphen in Form von Subjekt-Prädikat-Objekt-Sätzen gespeichert sind, könnten nach einer linguistischen Analyse der LLM-Antwort die Aussagen des LLM überprüft und gegebenenfalls korrigiert werden.
Warum reicht nicht nur ein Knowledge Graph?
Wenn Knowledge Graphen dieses Potenzial haben, wofür brauche ich dann ein LLM? Die Antwort liegt in der Zugänglichkeit des Knowledge Graphen für die Anwenderinnen und Anwender in doppelter Form.
Zum einen ist zwar die Abfrage des Knowledge Graph technisch einfach, doch bedarf es trotzdem des Wissens um eine Abfragesprache wie SPARQL oder ähnlichen und der Berechtigung, auf den Knowledge Graph direkt zugreifen zu können. Beides ist im Normalfall nicht gegeben.
Und zweitens hat die Antwort einer solchen Abfrage die oben erwähnte Triplestruktur von Subjekt-Prädikat-Objekt-Sätzen, die noch von technischen Notwendigkeiten wie Namespaces und Ausgabeformaten weiter verschleiert sein können.
Letztlich ist den meisten Anwenderinnen und Anwendern eine natürlichsprachliche Interaktion mit dem Wissen ihres Unternehmens deutlich lieber und damit für das Unternehmen wertvoller.
Die Aufgabe des LLMs ist gleichzeitig seine größte Stärke: Die Schnittstelle zwischen Menschen und Computersystem in der Sprache des Menschen auszufüllen, nicht in der Sprache des Computers!
LLM zur Erweiterung des Knowledge Graphen
Andersherum kann nicht nur der Knowledge Graph das LLM auf ein höheres Niveau heben, sondern auch das Sprachmodell dazu beitragen, den Knowledge Graphen weiterzuentwickeln. Das funktioniert, indem man LLMs z. B. als semantische Annotatoren arbeiten lässt.
Wenn ich ein LLM nach den inhaltlichen Metadaten des hier zu lesenden Textes frage, antwortet es mit einer Liste von 24 Schlüsselwörtern, die mit “LLM”, “Knowledge Graph”, “RAG-System”, “Halluzination”, “Value Proposition” beginnt.
Auf solche Weise können Texte klassifiziert, analysiert und in den Knowledge Graphen eingeordnet werden. Ob man hier auf Human-in-the-Loop-Ansätze zurückgreifen will und wie weit der Prozess zu automatisieren ist, hängt vom jeweiligen Use-Case und der Komplexität des zugrundeliegenden Metadatenmodells ab.
In Kürze: Vorteile, wenn wir das LLM mit Knowledge Graph verbessern
Nochmal zusammengefasst: Knowledge Graphen sind notwendig, wenn Informationen in komplexen, vernetzten und langfristig verwaltbaren Strukturen dargestellt werden müssen. Sie ermöglichen eine effiziente Verarbeitung, Verknüpfung und Abfrage von Daten, die weit über die Fähigkeiten eines Sprachmodells hinausgehen, das nur auf Textdokumenten trainiert wurde.
Alle Vorteile von Knowledge Graphen als Unterstützung von LLMs auf einen Blick:
- Komplexe Verknüpfungen und Beziehungen: Knowledge Graphen stellen logische Verknüpfungen zwischen Entitäten her und ermöglichen tiefere Analysen über verteilte Dokumente hinweg.
- Kontextsensitivität und Bedeutung: Sie speichern und verknüpfen Kontext explizit, sodass Begriffe und Konzepte in ihrer jeweiligen Bedeutung verstanden werden.
- Strukturierte und unstrukturierte Daten: Knowledge Graphen integrieren verschiedene Datenquellen und ermöglichen eine einheitliche, durchsuchbare Wissensbasis.
- Konsistenz und Wissensmanagement: Sie erlauben gezielte Aktualisierungen und stellen sicher, dass Wissen strukturiert, konsistent und wiederverwendbar bleibt.
- Skalierbarkeit und Langfristigkeit: Sie wachsen mit der Datenmenge, verbessern sich kontinuierlich und ermöglichen langfristiges, nachhaltiges Wissensmanagement.
- Reduzierung von Halluzinationen: Knowledge Graphen stellen sicher, dass KI-Modelle auf überprüfbare und logisch verknüpfte Informationen zurückgreifen, wodurch spekulative oder falsche Antworten minimiert werden.
In der Anwendung geht es nicht darum, die Systeme aus Freude an der Technologie umzusetzen, sondern konkret auf die Stakeholder abgestimmte Use-Cases zu optimieren. Bei allen technischen Finessen: Die Anwenderinnen und Anwender stehen im Vordergrund. Knowledge Graphen und Textdokumente stellen den Nutzern verlässliche Informationen zur Verfügung. LLMs aber erwecken die Informationen zum Leben. Der tatsächliche Mehrwert ergibt sich also erst aus einer Kombination eines LLM mit Knowledge Graph!

Jonathan Schrempp
Senior Knowledge Engineer | PANTOPIX
Wir informieren Sie gerne regelmäßig über neue Artikel, Videos oder Podcast-Folgen.

Knowledge
Erfahren Sie mehr über das Vernetzen von Informationen