Why your AI support chat is giving the wrong answers - and how to solve it
26. August 2025
“How can I change the cathode on electron microscope XY?” could be a typical question that a service technician enters into an AI support chat. If the question answering system (QA) only has a generic AI without a product-specific context, the answers will also only be generic. It is likely that the answer is simply wrong or elementary information is missing – for example, the information that a special tool is required. In our environment of technical communication, however, it is essential that the answers are reliable and context-related and come from reliable sources. Only then is a technical Q&A a powerful tool. This raises the question for many companies of how they can improve their technical AI support chat.
The Retrieval Augmented Generation (RAG) method is used to integrate company-specific information into a language model. Briefly explained, documents are divided into pages or sections and written to a vector database. These vectors are matched with the user query. Although this method works quite well, it has major weaknesses if the question does not semantically match the possible answers.
Experience has shown that questions that are difficult to answer by a RAG chat in a technical environment are as follows:
Questions about definitions (What is a …) -> Problem: Ensuring the exact definition
Questions about hierarchies (What does … consist of?) -> Problem: potential incompleteness of information
Questions about related content (related docs, e.g. additional information from current reports) -> Problem: no linking of these types of information
Questions about specific characteristics -> Problem: too much similarity of information
Aggregation questions (number, sum, minimum, maximum) -> Problem: lack of context, no knowledge of the complete dataset
Comparison questions (e.g. comparison of the same feature in two products) ->Problem: Recognizing correlations
“Understanding of question” – analyzing the question and recognizing the concepts and contexts behind it – is therefore also a hurdle for a question answering system that has product-specific information available through RAG. One solution would be to use the AI only to make a classification or to specify the search query instead of generating a new answer. The answer would then simply come from the database at the end. But there is also another option.
How can an AI support chat with RAG be improved beyond this?
To further improve a QA system that uses RAG, we need a semantic structure that maps both the links between the data and their meaning. Knowledge graphs, which represent concrete information as nodes and their relationships as edges, are suitable for this. The basis for this is an ontology, for example a product ontology, which defines the relevant terms, categories and possible relationships.
In addition, we need metadata that not only describes data, but also helps us to understand its meaning. This includes contextual information such as the age of a piece of information or the source from which it originates, as well as semantic relations in the ontology. Such semantic metadata links information with levels of meaning and makes it machine-interpretable.
Excursus: The iiRDS standard as a semantic structure provider for technical RAG chats
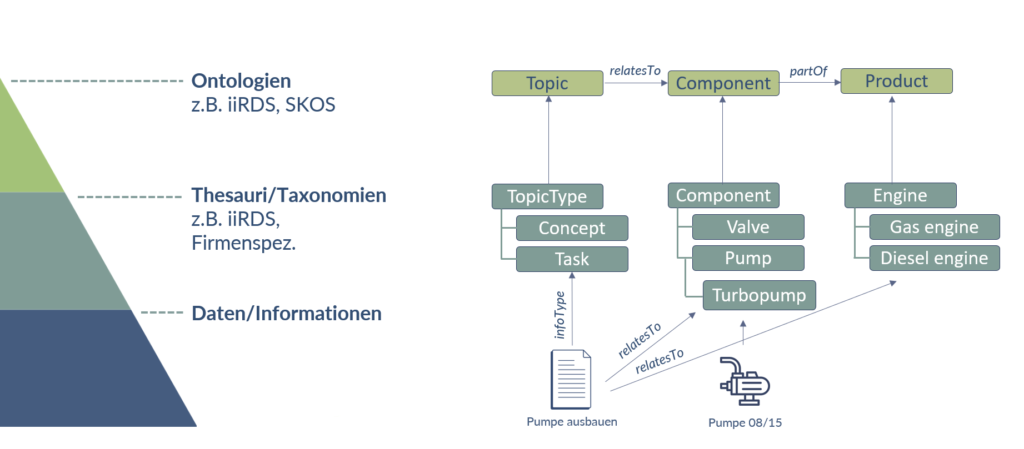
In technical writing, there is a good starting point for supplementing a technical Q&A with a semantic structure: iiRDS, a standard that specifies metadata for labeling technical information. It defines information types (e.g. concept or task), there is administrative and functional metadata and there is a small amount of product metadata (components and product feature).
Simple processes can only be mapped well with iiRDS classes: A topic references a component that is part of a product. This means that a component can be referenced in the technical documentation, for example, without the (variable) article number being mentioned. To do this, the procedure and component must be provided with a corresponding metadata, which makes it possible to find the specific article.
Outline of a simple product ontology using iiRDS
If the structure to be mapped for the technical Q&A is more complex than this, the information world of this standard can also be extended. New classes or subclasses of the specified iiRDS classes can be created. In addition, new classes can be linked to those of the standard in order to create a new product ontology or extend an existing one.
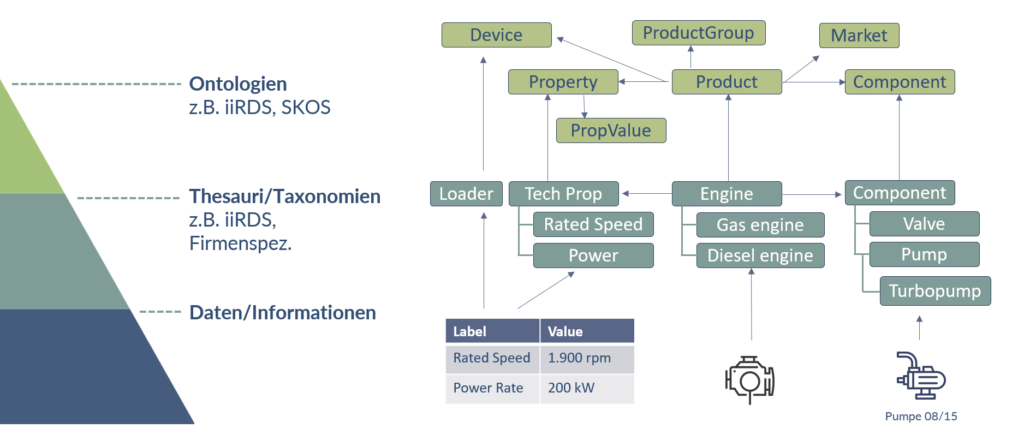
What does an extended iiRDS product ontology look like in practice?
Outline of an expanded product ontology based on iiRDS
“How do I replace the pump on the drive of my L50 machine? But it’s the US model. What is the rated speed of the drive?” A question like this is so complex for an AI support chat, even with RAG, that it requires a product ontology to answer. Because this question includes: Which product? Which component? Which market? What features?
Not everything can be answered from the iiRDS standard alone. To do this, the product ontology or its metadata model must be extended by four classes: a market class, a device class (the relationship between device and product), a property class and a property value class. The last two as a world for the feature definition.
A question such as the nominal speed can now be answered because the information object (in this case a table with technical data containing these values) is referenced with both a product and a device. This enables the QA system to distinguish which is the correct data source.
Advantages of semantics in technical Q&A
Adding semantic product data to a question answering system that uses RAG improves the quality of the answers.
Categorizing knowledge makes searching for information more efficient.
Structured data leads to relevant answers because the language model better understands the context and relationship between concepts.
Users can find the information they need more easily in complex topics because navigation has been improved.
By comparing user questions with known concepts, the system better recognizes the intention and interest of the user.
Outlook: Semantics as a compass for AI systems
Modern question-answering systems such as an AI support chat are already important tools for answering user questions efficiently. With the further development of generative AI and its growing autonomy, the The importance of semantic information must increase in order to guide AI responses and decisions. One way to achieve this is to use semantic structures such as product ontologies, enriched with meaning-creating metadata.
Both in the direct provision of information, e.g. in a portal or in a chat, this improves the findability, manageability, relevance and analysis or extraction of information. In this way, we can create a guard rail for the increasing autonomy of AI – AI agents are in the starting blocks. For us in technical communication, this should be motivation enough to systematically drive forward the maintenance of metadata and product ontologies and make targeted use of technologies such as knowledge graphs.