Improving LLM with Knowledge Graph: How to create a powerful AI combination
18. February 2025
Out-of-the-box solutions for RAG systems (Retrieval Augmented Generation) are becoming increasingly widespread. They promise to make a company’s knowledge accessible from documents such as PDFs or Word files using Large Language Models (LLMs) in the form of a chat. In this context, the question inevitably arises: Can’t we improve an LLM with Knowledge Graph? What role do knowledge graphs still play in this scenario and what added value can they offer?
In other words: If I can make all my texts available via chat, why should I invest money and time resources in structuring my knowledge?
From the perspective of a company that already uses these resources, i.e. has a knowledge graph available, the question arises as to whether an LLM can still offer added value. This is especially true as LLMs are known for their hallucinating and false information.
Structured data for the Large Language Model (LLM)
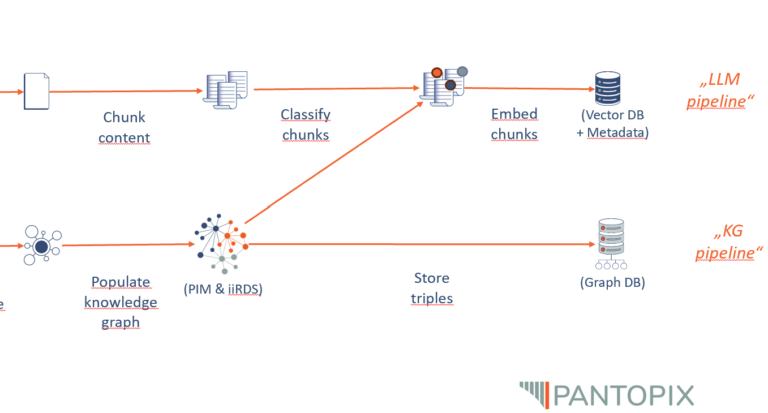
In order to make text files such as PDFs available for an LLM-driven chat, the text files must be broken down into meaningful sections (chunking) and each text section must be converted into vectors (embeddings) and saved (vector database). Based on this, when a request is sent to the chat, the request itself is vectorized and the semantically most obvious text section is returned to the LLM using mathematical-geometric functions and reformulated by the LLM into the final answer.
What is not trivial here is the granularity at which the meaning sections are to be selected (documents, chapters, pages, paragraphs, sentences) and how close the query and source vectors should be to each other in order to be considered relevant in terms of content. Methods in which the text sections are enriched with metadata (topic, author, text form, position, etc.), which in turn are included in the embeddings and thus sharpen the position in the semantic space, can be helpful, but must be individually adapted to the existing data and are therefore not available out-of-the-box.
This is precisely the strength of the Knowledge Graph and the answer to the question of how we can improve an LLM with Knowledge Graph technology. In the graph, the overall context of an individual piece of information is created from the outset and can be accessed in any depth and breadth via simple queries (SPARQL queries). For a chat system, this means that once the user query has been assigned to a topic, the answer can be put together from information modules that fit the context without having to rely on the structure of the semantic vector space.
Furthermore, the information in a knowledge graph is easily accessible, dynamically and modularly customizable, up-to-date and curated. Therefore, the knowledge encoded in the knowledge graph can not only contribute to the context expansion of the LLM, but can also be used to validate its output. Since, from a syntactic point of view, the information in the knowledge graph is stored in the form of subject-predicate-object sentences, the statements of the LLM can be checked and, if necessary, corrected after a linguistic analysis of the LLM response.
Why is a knowledge graph not enough?
If knowledge graphs have this potential, why do I need an LLM? The answer lies in the accessibility of the knowledge graph for users in two ways.
On the one hand, querying the Knowledge Graph is technically simple, but it still requires knowledge of a query language such as SPARQL or similar and authorization to access the Knowledge Graph directly. Neither of these is normally the case.
And secondly, the answer to such a query has the above-mentioned triple structure of subject-predicate-object sentences, which can be further obscured by technical necessities such as namespaces and output formats.
Ultimately, most users prefer to interact with their company’s knowledge in natural language, which is more valuable for the company.
The task of the LLM is also its greatest strength: to fill the interface between people and computer systems in the language of people, not the language of computers!
LLM to expand the knowledge graph
Conversely, not only can the knowledge graph raise the LLM to a higher level, but the language model can also contribute to the further development of the knowledge graph. This works by allowing LLMs to work as semantic annotators, for example.
When I ask an LLM for the content metadata of the text to be read here, it responds with a list of 24 keywords beginning with “LLM”, “knowledge graph”, “RAG system”, “hallucination”, “value proposition”.
In this way, texts can be classified, analyzed and sorted into the knowledge graph. Whether you want to use human-in-the-loop approaches here and the extent to which the process can be automated depends on the respective use case and the complexity of the underlying metadata model.
In a nutshell: Benefits of improving LLM with Knowledge Graph
To summarize once again: Knowledge graphs are necessary when information needs to be represented in complex, networked structures that can be managed over the long term. They enable efficient processing, linking and querying of data that goes far beyond the capabilities of a language model that has only been trained on text documents.
All the advantages of Knowledge Graphs as support for LLMs at a glance:
Complex links and relationships: Knowledge graphs create logical links between entities and enable deeper analysis across distributed documents.
Context sensitivity and meaning: They explicitly store and link context so that terms and concepts are understood in their respective meanings.
Structured and unstructured data: Knowledge graphs integrate different data sources and enable a standardized, searchable knowledge base.
Consistency and knowledge management: They allow targeted updates and ensure that knowledge remains structured, consistent and reusable.
Scalability and longevity: They grow with the amount of data, improve continuously and enable long-term, sustainable knowledge management.
Reduction of hallucinations: Knowledge graphs ensure that AI models draw on verifiable and logically linked information, minimizing speculative or incorrect answers.
The application is not about implementing the systems for the joy of technology, but about optimizing specific use cases tailored to the stakeholders. Despite all the technical finesse: The focus is on the users. Knowledge graphs and text documents provide users with reliable information. LLMs, however, bring the information to life. The real added value therefore only comes from combining an LLM with a knowledge graph!