23. September 2025
Knowledge graphs – also known as knowledge graphs – are one of the top trends in applied artificial intelligence. According to the Gartner Trend Report, graph-based technologies will be used in around 80% of all data and analytics innovations in 2025 (in 2021, the figure was just 10%). The use of knowledge representation is also increasingly being discussed in technical communication. The technology has long been used to model knowledge and map complex relationships. In combination with generative AI, the knowledge graph becomes an even more powerful tool for efficiently organizing knowledge, recognizing relationships and enabling intelligent applications. But what does this buzzword actually mean and what are the benefits of introducing knowledge graphs in companies?
What is a knowledge graph?
Knowledge graphs are used in technical communication to link complex product information in a structured way and make it usable for both people and machines.
A knowledge graph is a structured representation of knowledge in the form of a semantic network. Information is linked together via nodes (entities) and edges (relationships).
This allows information silos to be broken down and company-specific knowledge – for example on products, components or functions – to be consistently modeled and reused. It does not matter whether the underlying data is structured or unstructured.
Semantics as the foundation of knowledge graphs
Knowledge graphs are often described as “semantic networks,” but what does that actually mean?
Semantics refers to the meaning of information and its context. In technical communication, the goal is not merely to store content, but to structure it in such a way that both machines and humans can clearly understand its meaning. This is precisely where the knowledge graph comes into play: it connects information not only technically, but also in terms of content.
While traditional data structures often manage isolated pieces of information, semantic modeling focuses on relationships and connections. Terms such as “product,” “component,” or “spare part” are not merely listed but clearly defined in terms of their meaning and linked to one another. This fosters a shared understanding of the data across systems and departments.
This is based on semantic models such as ontologies, taxonomies, and controlled vocabularies. These ensure that information is described consistently and can be interpreted correctly in different contexts. It is only through this semantic structure that it becomes possible to make knowledge machine-readable and link it intelligently.
Knowledge graphs use these semantic models to link information in a context-aware manner. This enables systems to recognize relationships, draw conclusions, and deliver content in a targeted manner—for example, in semantic search or AI-powered assistant systems.
To learn more about how semantics is used in technical communication and the role it plays in structured content, read our article on the meaning of semantics in technical communication.
How does a knowledge graph work?
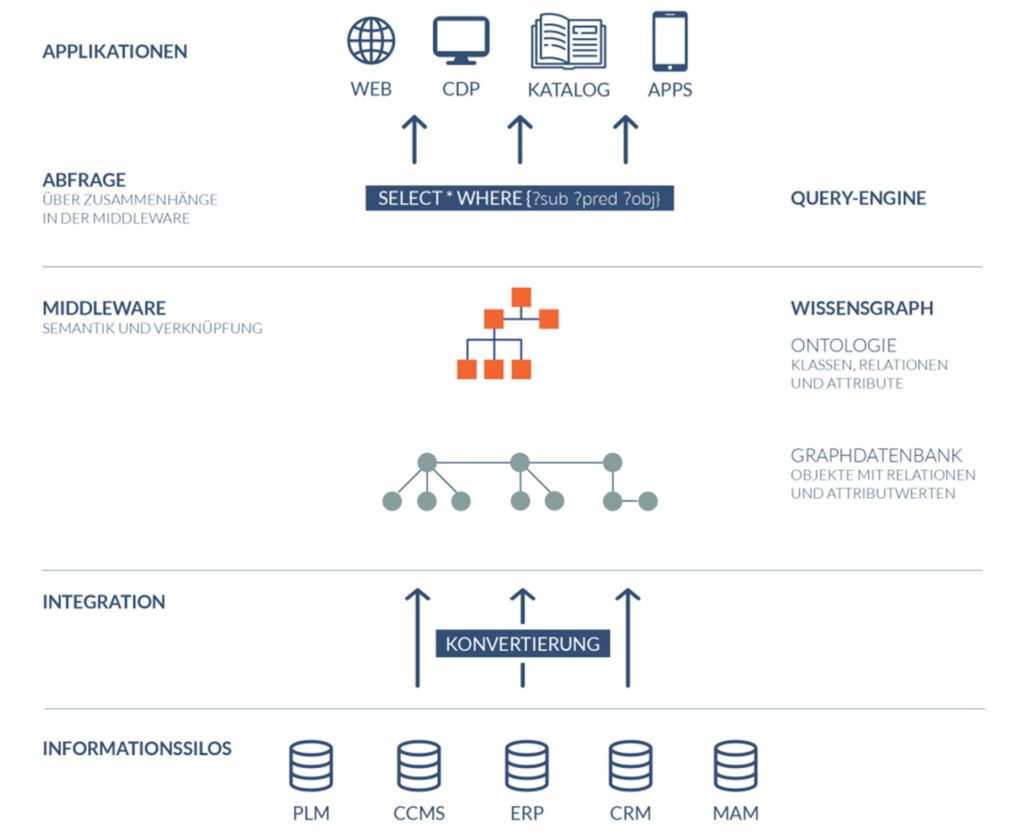
In brief: A company’s knowledge is first described in a clear, standardized form, such as an ontology. Data from different data silos is merged, harmonized and enriched with metadata. This semantic enrichment creates a uniform context in which information is not only stored but also linked to one another.
The result is a machine-readable knowledge network that can be used flexibly. Knowledge graphs can be used in companies for many purposes, for example for intelligent assistants, more precise semantic search queries, automated analyses or for the development of new data-driven services. The more data is integrated, the more valuable and meaningful the knowledge graph becomes, because it makes connections visible that were previously hidden.
To help you understand, we’ve created a video that explains knowledge graphs in simple terms.
How to create knowledge graphs
Describing a knowledge domain with an ontology
The basis for a knowledge graph is an ontology. “An ontology is the explicit, formal representation of the knowledge of a specific domain,” explains Dr. Martin Ley, Professor of Information Management at Munich University of Applied Sciences. The domain is the subject area that the ontology covers. The ontology defines which classes of objects exist in the domain and how these objects (nodes) relate to each other (edges). The objects can be enriched with additional information, e.g. source, time or format, via further properties.
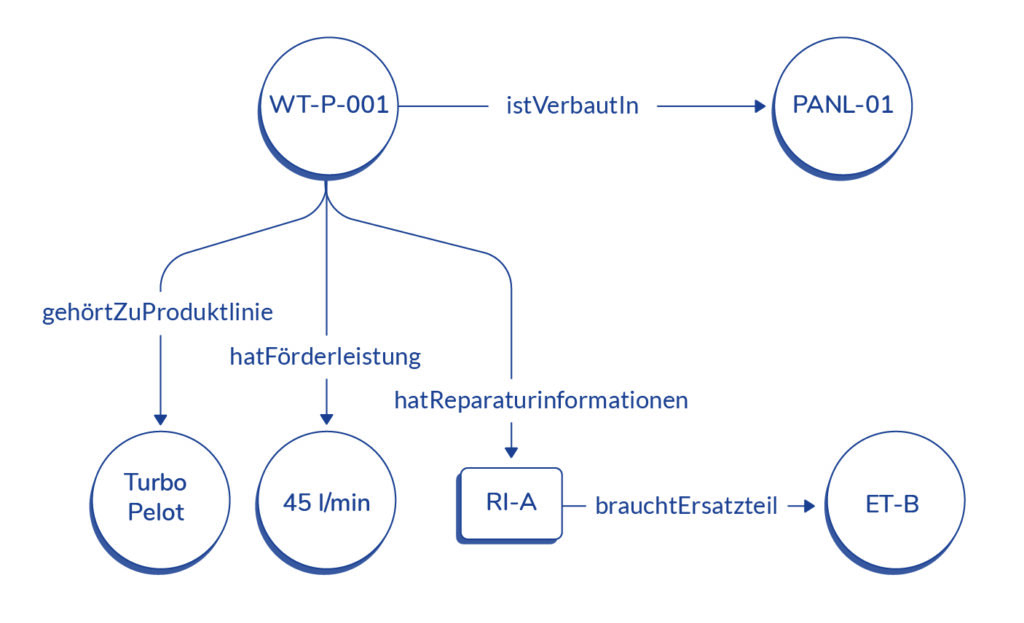
Examples of possible classes of objects in our context of technical communication are products and their components and parts, but also repair information or spare parts. Typical relationships are that a product consists of components or that repair information belongs to a component. This information content can be represented in so-called directed graphs. These are relationships (edges) that have a specific direction.
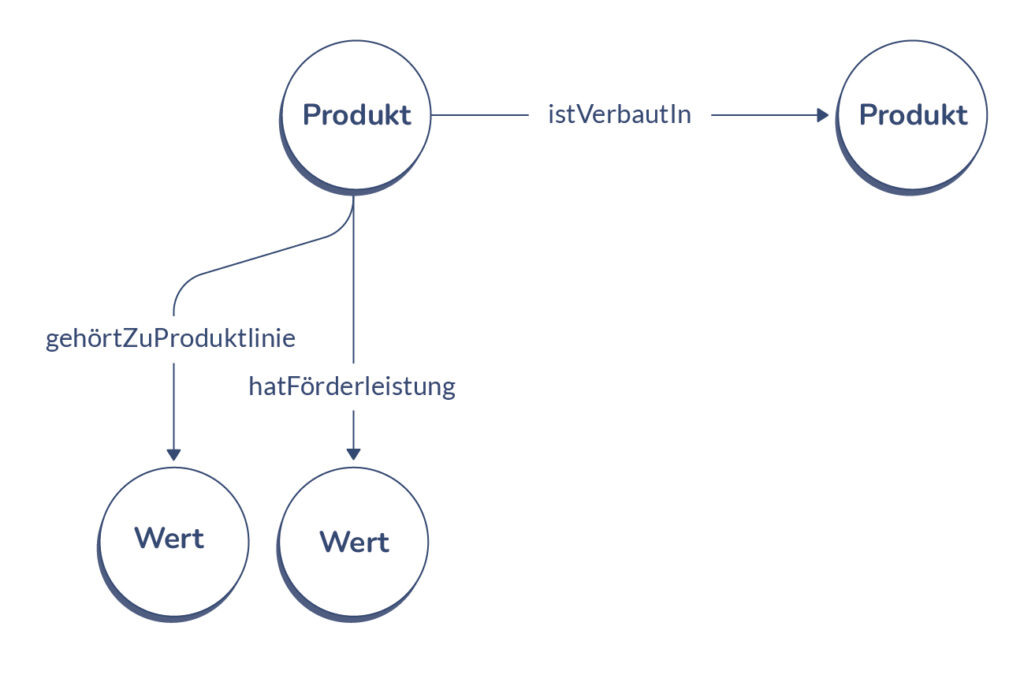
To make this representation machine-readable, it is expressed in a specific description language such as RDF (Resource Description Framework).
Specialized tools are used to model such ontologies in computer science, which support the creation, structuring and validation of knowledge models. The finished models are then stored in a graph database, where they can be flexibly queried and expanded. As a partner of various providers, we advise our customers on the selection and implementation of the right solution.
Specific content in the graph database
Once the basis for the knowledge model has been created as an ontology, the information is exported from the various data silos, transformed and mapped as so-called “proxy objects” in a graph database. These representatives, also known as instances, are the concrete data that represent the abstract classes of the ontology. This enables relations to exist between the real data as well.
This networked information is an excellent basis for value-adding business and service processes.
Challenges in knowledge modeling and knowledge graph construction
“The challenge in modeling an ontology is to identify the classes and relations that are relevant for future applications. As a rule, existing metadata concepts, information models or nomenclatures are used and processed automatically,” explains Dr. Martin Ley. “When building the knowledge graph, it is also challenging that product knowledge is usually stored in many different places in the company for historical reasons. Product-related information is stored in the PLM system, technical documentation in a CCMS and information for sales in a CRM system, etc.”
This requires one or more conversion tools that automatically transfer existing information into the graph database for specific use cases. “Simple mapping is often used, as the information is usually structured or semi-structured. If the information cannot be mapped adequately, additional functionalities such as text mining or entity extraction may help,” says Dr. Martin Ley.
This is precisely where our PANTOPIX SPHERE platform comes in: It automates many of these conversions, integrates information from different source systems and provides reliable, semantically linked data for a wide range of applications on the basis of a central knowledge graph.
This networked information is an excellent basis for value-adding business and service processes.
Possible applications of semantic knowledge structures
Knowledge graphs incorporate different types of information from different areas of the company and offer a 360-degree view of the company. A wide range of application scenarios can be derived from this:
- Semantic search: They enable better search results because the search is based on context and not just keywords.
- Intelligent assistants and chatbots: These systems use knowledge graph technology to answer questions precisely and contextually.
- Data integration: Different data sources are linked and standardized so that correlations become visible.
- Better support: Service cases are resolved more quickly and in a more targeted manner because all relevant information is linked.
- Knowledge management: Companies organize and use their specialist knowledge more efficiently.
- Recommendation systems: In the form of apps, they support sales staff or customers directly in the selection of products that require explanation.
Application examples: Graph-based information in practice
The benefits of knowledge graphs become particularly evident when they are used as the semantic foundation for business-critical systems. In this context, they link information from various sources, establish consistent relationships, and enable the intelligent use of corporate knowledge.
CCMS and Technical Documentation
In Component Content Management Systems (CCMS), knowledge graphs help link content, products, variants, and target audiences. This enables technical information to be delivered and reused in a more targeted manner.
→ Learn more about the benefits of integrating a CCMS with a knowledge graph.
Product Information Management (PIM)
Knowledge graphs extend traditional PIM systems by adding semantic relationships between products, attributes, standards, and application areas. This improves data quality, product search, and automation.
→ Learn more about integrating PIM systems with Knowledge Graph.
Digital Product Passport (DPP)
The Digital Product Passport requires the integration of information from development, production, the supply chain, and service. Knowledge graphs create the necessary connections between these data points and thus form an important foundation for DPP solutions.
→ Learn more about the role knowledge graphs can play in the digital product passport.
LLMs and Artificial Intelligence
Studies have shown that GraphRAG—that is, RAG that draws on structured data from a knowledge graph—delivers results that are 40% better.
→ Read our article about the connection between AI and knowledge graphs.
→ In the video, we explain the synergy between knowledge graphs and LLMs.
CPQ Software in Sales
By semantically linking product knowledge, knowledge graphs help sales representatives and customers configure highly complex products and ensure faster, more consistent quoting processes.
Service and support
A knowledge graph-based application is an intelligent service assistant, such as ZEISS Service Copilot. It provides all relevant information—such as repair instructions, replacement parts, and work values—tailored to specific products and contexts. An additional AI chatbot makes searching through hundreds of documents, such as manuals and troubleshooting guides, more efficient. Clear citations ensure the quality of the AI’s responses.
Another example of the creation and application of a knowledge graph-based approach is described in our white paper “Step by step to the knowledge graph”. Using the use case of a pump manufacturer, you will learn how we have transferred product knowledge in tables to networked information in a knowledge graph.
Advantages of knowledge graphs in companies
In technical communication, knowledge graphs are a key technology that enables companies to leverage their valuable information for a wide range of future-proof applications—rather than simply managing it in various data silos. AI applications also benefit from semantically enriched information: Large language models (LLMs) are known to have weaknesses regarding the factual accuracy of their responses and a tendency to hallucinate. However, the demands on the quality and timeliness of technical information are extremely high. The combination of knowledge graphs and LLMs takes both technologies to a new level.
The special thing about using a semantic knowledge network is its flexibility and scalability. It is possible to start networking valuable knowledge today with a small amount of information and systems and gradually integrate additional subject areas and information sources. This ensures that the investment in a knowledge graph-based technology is an investment in the future.
The use of semantic knowledge structures brings many benefits:
- Knowledge is better networked so that connections between different pieces of information become visible
- Decisions can be made faster and more confidently thanks to a well-founded overview
- Data from different sources and systems can be merged
- Various departments such as service or support can answer queries more quickly and in a more targeted manner
- Processes such as recommendation management can be automated
- Networked information makes it easier to develop new solutions and innovations and is an outstanding basis for a wide range of portals
- Knowledge graphs are at the heart of data-driven applications such as recommender systems, dashboards or customer 360 views
- Compliance and quality assurance are supported by transparent data
Authors: Sandy Hedig, Marketing Manager at PANTOPIX, in collaboration with Dr. Martin Ley, Professor of Information Management at Munich University of Applied Sciences.
Status: August 2025

Dr. Martin Ley
Managing Director | PANTOPIX

Sandy Hedig
Marketing Manager | PANTOPIX
We will be happy to inform you regularly about new articles, videos or podcast episodes.

Knowledge
Learn more about connecting information


