



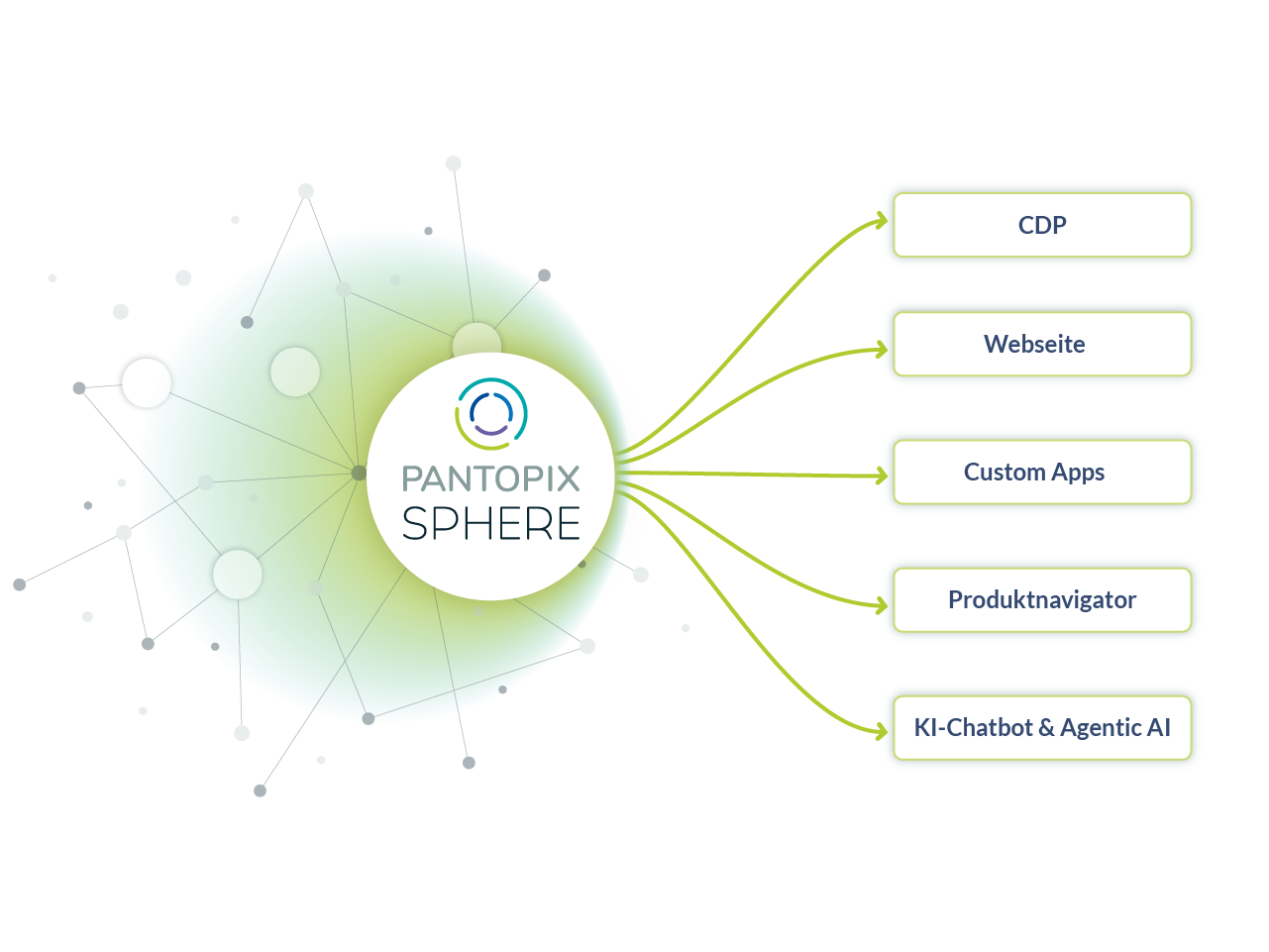

"The digital product passport is not an isolated task. It shows how important networked, consistent and structured information has become and is therefore the starting point for better information architectures."


"The digital product passport is not an isolated task. It shows how important networked, consistent and structured information has become and is therefore the starting point for better information architectures."