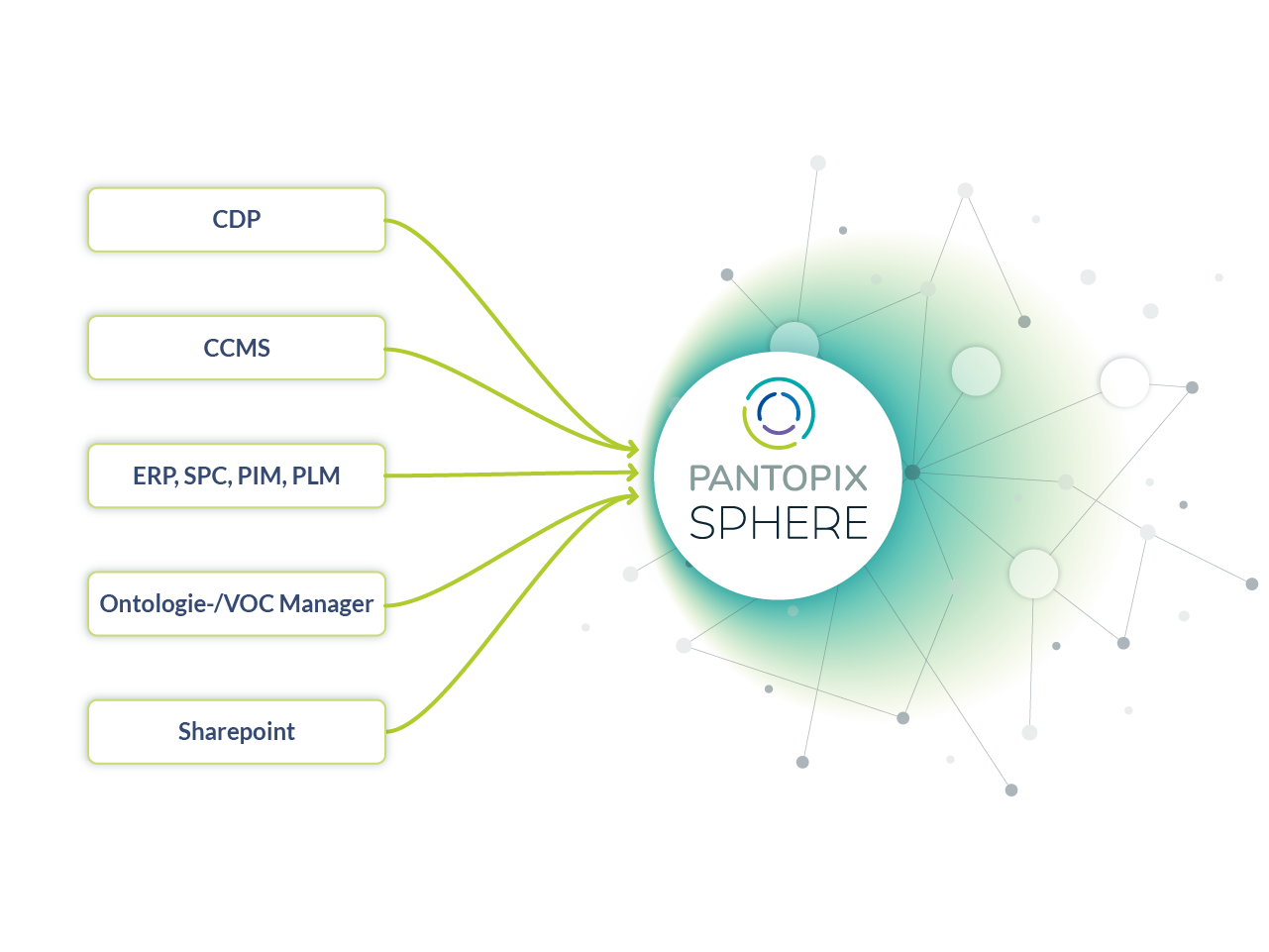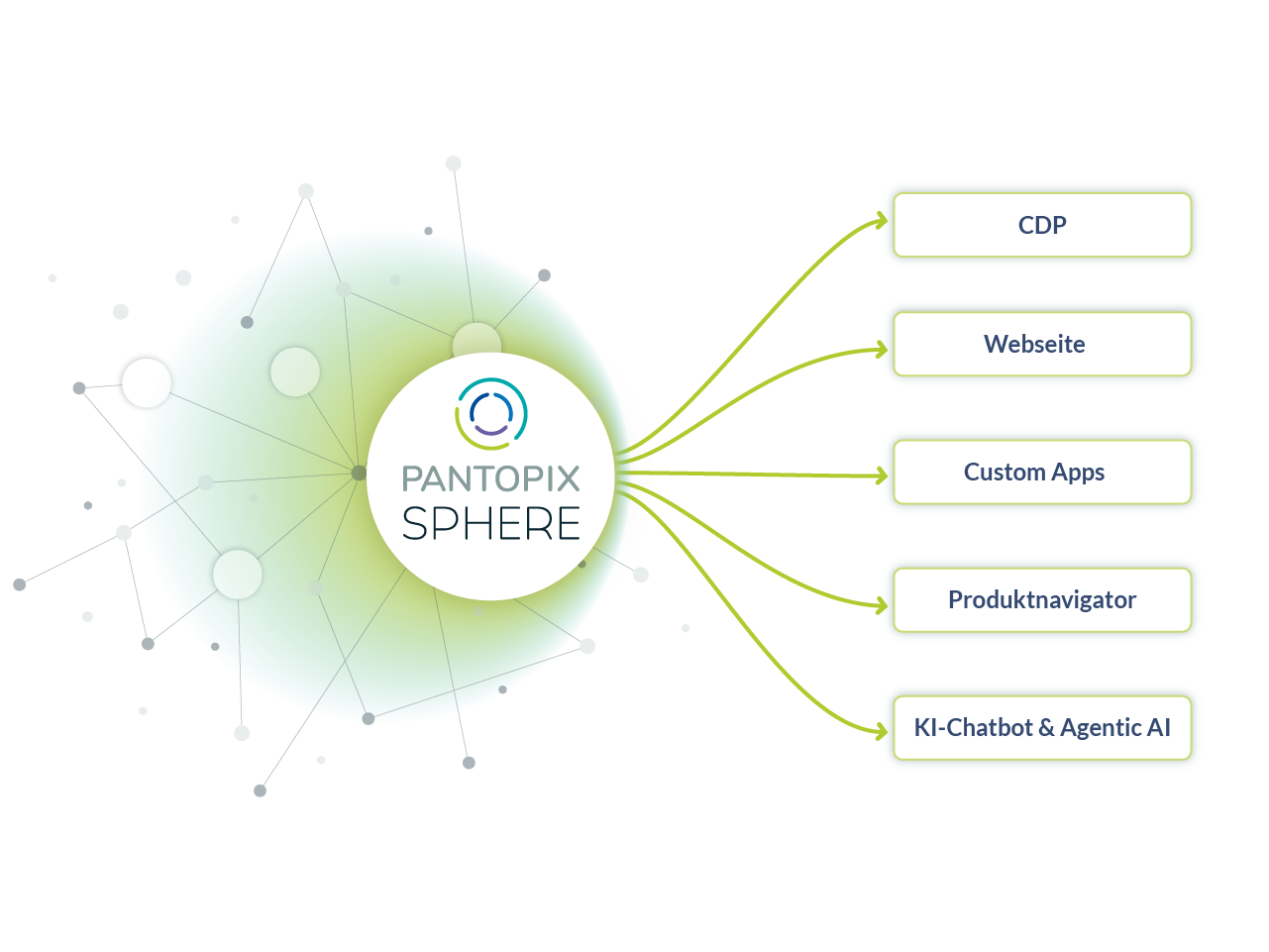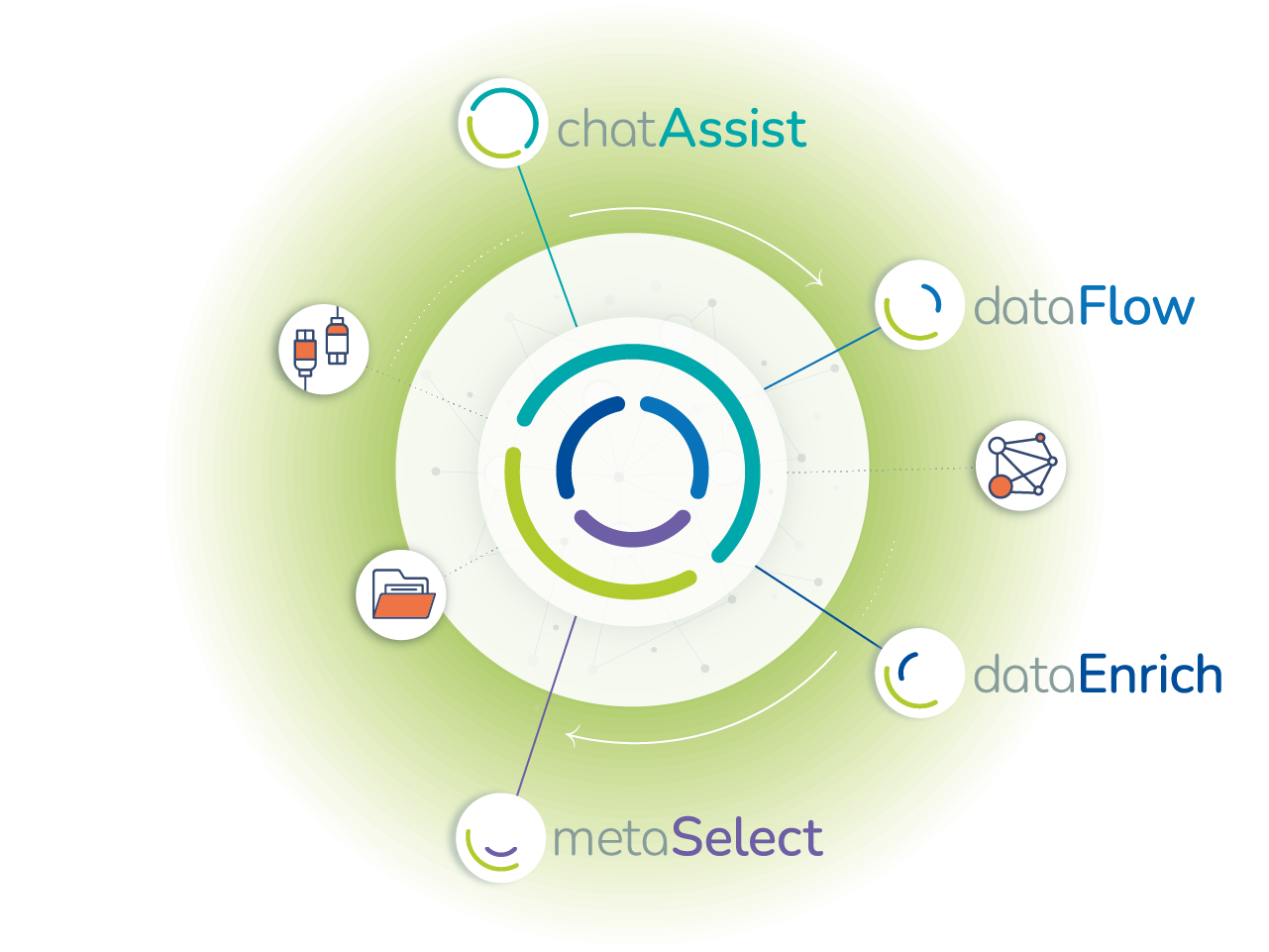
01 metaSelect for intelligent metadata management

02 dataFlow for automated data flows

03 dataEnrich for automated data enrichment

04 chatAssist for intuitive access to knowledge