Improving Highly Configurable Quote Generation with CPQ Software, DITA, and a Knowledge Graph

19. June 2026
Problem: Content as the Scaling Limitation of CPQ Software
The digitalization of sales processes is already well advanced. CPQ software automates product configuration, pricing, and quote generation, enabling customers to independently assemble solutions and request quotes digitally.
What is often underestimated: the scalability of this process does not fail at configuration – it fails at content. Especially with highly variable products, quotes must not only correctly represent technical parameters but also deliver context-specific content. Information must appear only when it matches the respective configuration. This type of content control cannot be achieved with document-centric approaches.
The root cause lies in the underlying logic. Traditional quote generation software is document-centric. It combines existing files and inserts variables. Content is typically managed as Word documents, while key capabilities such as structured authoring, content management, translation logic, and configuration-dependent selection are missing.
In practice, this leads to systematic issues. A product appears multiple times in a quote in different configurations, while marketing content is redundantly repeated. Content is copied instead of controlled, creating inconsistencies. As product variability increases, maintenance effort grows exponentially. The following case illustrates this problem.
Initial Situation and Requirements for Quote Generation for Highly Configurable Products
At DITA Europe 2026, I presented a solution approach that we implemented for one of our mechanical engineering clients with highly configurable products. The client wanted to further digitize its sales processes so that customers could independently assemble individual product combinations via a webshop and request quotes based on them.
The generation of these quotes was to be automated via SAP CPQ software following the “Configure – Price – Quote” logic and consist of two parts:
The technical section should include product-specific properties, variants, prices, and USPs, and could appear multiple times in the document if a product is included in different configurations. The marketing section, on the other hand, should contain additional value propositions and product benefits and appear only once in the quote, regardless of the number of configurations per product.
The technical implementation in the existing system was based on a document-centric logic. SAP CPQ generated quotes based on a file stack of Word documents. Technical properties were embedded directly into these documents via a proprietary variable mechanism from the SAP configuration.
However, to realize digital quote generation for such highly configurable products, this SAP CPQ tool lacked key capabilities. These include structured authoring functionalities, metadata-based document management for underlying files, integrated mechanisms for translation and language logic, and algorithms for intelligent selection and assembly of content based on specific product combinations.
While configuration and pricing logic are mapped in the CPQ system, a comparable system for generating consistent, context-dependent content in quotes is missing.
Solution Combines CPQ Software with DITA and a Knowledge Graph
Our solution consistently builds on existing systems, content, and structures and integrates them into a comprehensive content architecture for quote generation. This includes:
- Existing content in SAP tables already used for quote documents
- The existing DITA-based CCMS (Tridion Docs) for structured content creation and document delivery
- The existing taxonomy as a foundation for metadata and filtering logic
- The existing PIM system providing technical data for non-configurable products
Architecture: Interplay of Content, Data, and Context
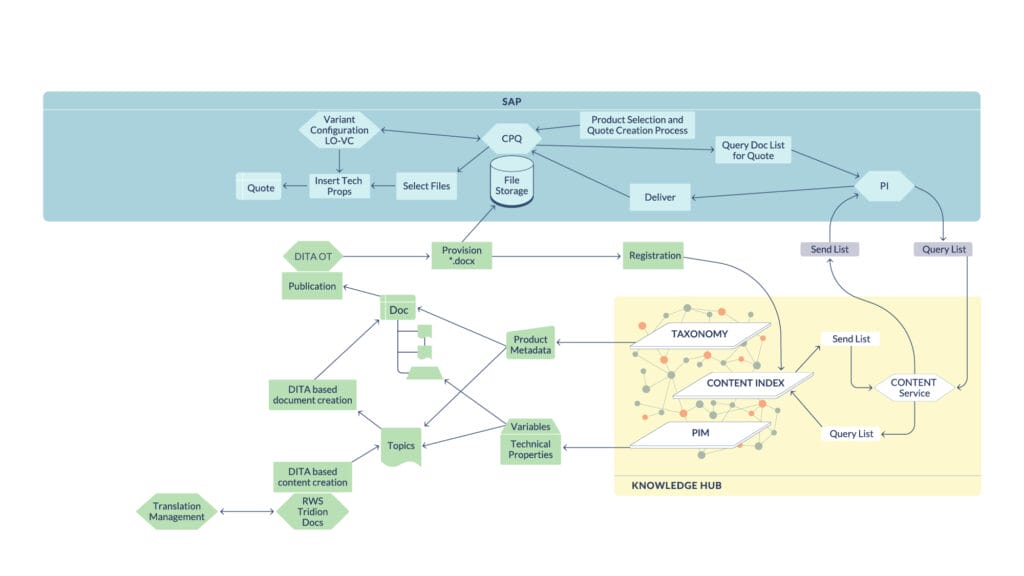
A Knowledge Hub forms the central integration and context layer of the solution architecture. It combines taxonomy, content index, and product data from the PIM into a shared semantic model and links content, metadata, and technical product information across systems. This creates the context in which content is interpreted and used.
Based on this, metadata controls the specific selection of content. It determines which content modules are included or excluded depending on the respective product configuration, while recurring values are centrally defined and contextually integrated. Combined with the structured, modular content base in DITA, this results in configurable content that can flexibly adapt to different variants without requiring redundant maintenance.
The actual generation of quote documents is then handled via the DITA Open Toolkit pipeline. The selected content is transformed into the target format—in this case, Word documents—and transferred to the CPQ system. The document is thus created only at the end of the process as a rendering result, rather than serving as the starting point.
Communication between the involved systems—CCMS, Knowledge Hub, and CPQ—takes place via REST APIs and process engines. This results in a loosely coupled, scalable architecture in which content, data, and documents can be efficiently orchestrated.
Data Origin and Single Source of Truth
An important aspect concerns the origin of technical product data. For configurable products, properties and values are already taken directly from the SAP configurator. For non-configurable products, however, this information is still part of the content in the CCMS, even if it is integrated via variable mechanisms. This leads to redundancies and potential inconsistencies compared to product data maintained in the PIM or Knowledge Hub.
In a future expansion stage, these values will also be fully sourced from the Knowledge Hub, establishing a consistent “single source of truth” for technical product information.
The Human Factor
A key success factor in the solution was the transformation of marketing workflows. The authors involved had to implement fundamental changes to their processes and tools within a short period of time.
Instead of working on SAP interfaces, they began using a CCMS. Content was no longer maintained in simple, flat structures but created in DITA as structured, modular content. This also required conscious handling of metadata, which was no longer implicitly defined by the system but had to be actively maintained and assigned.
Particularly significant was the shift from copy-paste logic to systematic variant control. Content was no longer created multiple times for each product variant but controlled via conditions and flexibly adapted using variables. Translation processes also underwent a fundamental change: instead of complex export and import procedures, integrated translation management was used. Additionally, authors had to adapt to explicit publication processes that had previously been largely implicit within the SAP system. Content now passes through clearly defined stages from creation to delivery.
Despite this transition, a clear effect quickly became evident. Within a short time, a highly reusable, variant-controlled content base was created using DITA. Authors adopted new ways of working and even developed a high level of acceptance and engagement with new capabilities.
Additional project example:
Another PANTOPIX project also demonstrates that this transformation is relevant not only to CPQ-related quoting processes. Our case study describes future-proof product communication using DITA, CCMS, and a content delivery portal. There, too, the focus is on structured content, metadata, and a scalable content supply chain.
Conclusion
The key insights from the project can be clearly summarized. DITA proves to be a central enabler, as without fast and structured content creation, the entire system remains empty. Equally important is the early involvement of authors, since even the best architecture is ineffective if it is not used. Training plays a crucial role – not only in understanding tools but also processes. Finally, knowledge graph approaches often have an impact beyond their original purpose, enabling improvements in areas that were not initially focused.
Overall, the role of content fundamentally shifts. It becomes the central infrastructure of a digital quote generation process. In this context, DITA, knowledge graphs, and CPQ systems are not isolated technologies but components of a unified architecture. Their interaction makes it possible to industrialize content and systematically overcome a major scaling barrier in variant-driven business models.
The article was published through the Center for Information and Development Management (CIDM).

Karsten Schrempp
Managing Director | PANTOPIX
We will be happy to inform you regularly about new articles, videos or podcast episodes.

Knowledge
Learn more about connecting information