19. Juni 2026
Problem: Content als Skalierungsgrenze der CPQ-Software
Die Digitalisierung von Vertriebsprozessen ist weit fortgeschritten. CPQ-Software automatisiert Produktkonfiguration, Preisermittlung und Angebotserstellung, sodass Kunden digital eigenständig Lösungen zusammenstellen und Angebote anfordern können.
Was dabei unterschätzt wird: Die Skalierbarkeit dieses Prozesses scheitert nicht an der Konfiguration, sondern am Content. Gerade bei variantenreichen Produkten müssen Angebote nicht nur technische Parameter korrekt abbilden, sondern kontextspezifische Inhalte liefern. Informationen dürfen nur dann erscheinen, wenn sie zur jeweiligen Konfiguration passen. Diese Form der inhaltlichen Steuerung ist mit dokumentenzentrierten Ansätzen nicht erreichbar.
Die Ursache liegt in der zugrunde liegenden Logik. Klassische Software für die Angebotserstellung arbeitet dokumentenzentriert. Sie kombiniert bestehende Dateien und fügt Variablen ein. Inhalte werden typischerweise als Word-Dokumente verwaltet, während zentrale Fähigkeiten wie strukturiertes Authoring, Content-Management, Übersetzungslogik und konfigurationsabhängige Selektion fehlen.
In der Praxis führt das zu systematischen Problemen. Ein Produkt erscheint mehrfach im Angebot in unterschiedlichen Konfigurationen, während Marketinginhalte redundant wiederholt werden. Inhalte werden kopiert statt gesteuert, was Inkonsistenzen erzeugt. Mit wachsender Variantenvielfalt steigt der Pflegeaufwand exponentiell. Der nachfolgende Anwendungsfall verdeutlicht diese Problematik.
Ausgangssituation und Anforderungen an die Angebotserstellung für hochgradig konfigurierbare Produkte
Bei der DITA Europe 2026 habe ich einen Lösungsansatz vorgestellt, den wir bei einem unserer Maschinenbau-Kunden mit hochgradig konfigurierbaren Produkten umgesetzt haben. Dieser wollte seinen Vertrieb weiter digitalisieren, damit seine Kunden über den Webshop eigenständig individuelle Produktkombinationen zusammenstellen und auf dieser Basis ein Angebot anfordern können.
Die Generierung dieses Angebots sollte automatisiert über die SAP CPQ-Software entlang der Logik „Configure – Price – Quote“ erfolgen und aus zwei Teilen bestehen: Der technische Teil sollte produktspezifische Eigenschaften, Varianten, Preise sowie USPs enthalten und mehrfach im Dokument erscheinen können, wenn ein Produkt in unterschiedlichen Konfigurationen enthalten ist. Der Marketingteil hingegen sollte weiterführende Nutzenargumentationen und Produktvorteile enthalten und unabhängig von der Anzahl der Konfigurationen pro Produkt nur einmal im Angebot erscheinen.
Die technische Umsetzung im bestehenden System basierte auf einer dokumentenzentrierten Logik. SAP CPQ erzeugte Angebote auf Grundlage eines Datei-Stacks aus Word-Dokumenten. Technische Eigenschaften wurden über eine proprietäre Variablenmechanik direkt aus der SAP-Konfiguration in diese Dokumente eingebunden.
Um jedoch eine digitale Angebotserstellung für so hochgradig konfigurierbare Produkte zu realisieren, fehlten diesem SAP CPQ-Tool zentrale Funktionen. Dazu gehören insbesondere strukturierte Authoring-Funktionalitäten, ein metadatenbasiertes Dokumentenmanagement für die zugrunde liegenden Dateien, integrierte Mechanismen für Übersetzung und Sprachlogik sowie Algorithmen zur intelligenten Auswahl und Zusammenstellung von Inhalten auf Basis konkreter Produktkombinationen.
Während die Konfigurations- und Preislogik im CPQ-System abgebildet ist, fehlt eine vergleichbare Systematik für die Generierung konsistenter, kontextabhängiger Inhalte im Angebot.
Lösung verbindet CPQ-Software mit DITA und Knowledge Graph
Unsere Lösung baut konsequent auf den bestehenden Systemen, Inhalten und Strukturen auf und integrierte diese zu einer durchgängigen Content-Architektur für die Angebotserstellung. Dazu gehören:
- die vorhandenen Inhalte in SAP-Tabellen, die bereits für Angebotsdokumente genutzt wurden
- das bestehende DITA-basierte CCMS (Tridion Docs) für strukturierte Content-Erstellung sowie für die Auslieferung von Dokumenten
- die bestehende Taxonomie, die als Grundlage für Metadaten und Filterlogiken dient
- das vorhandene PIM-System, das technische Daten für nicht-konfigurierbare Produkte bereitstellt
Architektur: Zusammenspiel von Content, Daten und Kontext
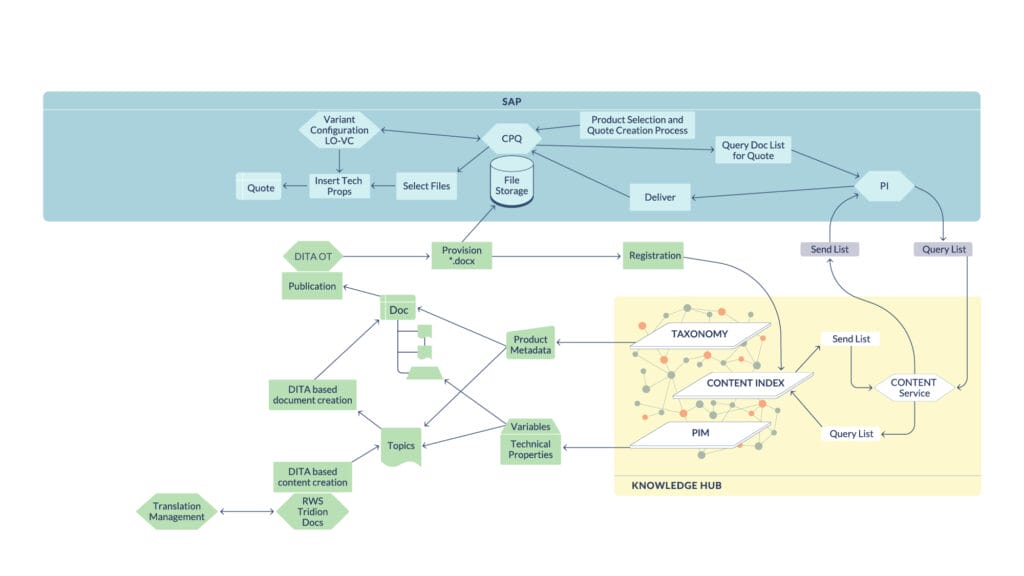
Ein Knowledge Hub bildet die zentrale Integrations- und Kontextschicht der Lösungsarchitektur. Er vereint Taxonomie, Content-Index und Produktdaten aus dem PIM in einem gemeinsamen semantischen Modell und verknüpft Inhalte, Metadaten sowie technische Produktinformationen systemübergreifend miteinander. Auf dieser Basis entsteht der Kontext, in dem Inhalte interpretiert und genutzt werden.
Aufbauend darauf steuern Metadaten die konkrete Selektion der Inhalte. Sie bestimmen, welche Content-Module in Abhängigkeit von der jeweiligen Produktkonfiguration ein- oder ausgeblendet werden, während wiederkehrende Werte zentral definiert und kontextabhängig eingebunden werden. In Kombination mit der strukturierten, modularen Content-Basis in DITA entsteht so konfigurierbarer Content, der sich flexibel an unterschiedliche Varianten anpasst, ohne redundant gepflegt werden zu müssen.
Die eigentliche Generierung der Angebotsdokumente erfolgt anschließend über die DITA Open Toolkit Pipeline. Dabei werden die selektierten Inhalte in das Zielformat – in diesem Fall Word-Dokumente – transformiert und in das CPQ-System überführt. Das Dokument entsteht somit erst am Ende des Prozesses als Rendering-Ergebnis und nicht mehr als Ausgangspunkt.
Die Kommunikation zwischen den beteiligten Systemen – CCMS, Knowledge Hub und CPQ – erfolgt über REST-APIs und Prozess-Engines. Dadurch entsteht eine lose gekoppelte, skalierbare Architektur, in der Content, Daten und Dokumente effizient miteinander orchestriert werden können.
Datenherkunft und Single Source of Truth
Ein wichtiger Aspekt betrifft die Herkunft technischer Produktdaten. Für konfigurierbare Produkte werden Eigenschaften und Werte bereits direkt aus dem SAP-Konfigurator übernommen. Bei nicht-konfigurierbaren Produkten hingegen sind diese Informationen aktuell noch Teil des Contents im CCMS, auch wenn sie über Variablenmechanismen eingebunden werden. Dies führt zu Redundanzen und potenziellen Inkonsistenzen gegenüber den im PIM bzw. Knowledge Hub gepflegten Produktdaten.
In einer nächsten Ausbaustufe ist daher vorgesehen, auch diese Werte vollständig aus dem Knowledge Hub zu beziehen und damit eine durchgängige „Single Source of Truth“ für technische Produktinformationen zu etablieren.
Die Variable Mensch
Ein zentraler Erfolgsfaktor der Lösung lag in der Transformation der Arbeitsweise im Marketing. Die beteiligten Autorinnen und Autoren mussten innerhalb kurzer Zeit grundlegende Veränderungen in ihren Prozessen und Werkzeugen vollziehen.
An die Stelle der bisherigen Arbeit in SAP-Masken trat die Nutzung eines CCMS. Inhalte wurden nicht mehr in einfachen, flachen Strukturen gepflegt, sondern in DITA als strukturierter, modularer Content erstellt. Gleichzeitig erforderte dies den bewussten Umgang mit Metadaten, die nicht länger implizit durch das System vorgegeben waren, sondern aktiv gepflegt und zugeordnet werden mussten.
Besonders relevant war der Wechsel von Copy-Paste-Logiken hin zu systematischer Variantensteuerung. Inhalte wurden nicht mehr für jede Produktvariante mehrfach erstellt, sondern über Bedingungen gesteuert und über Variablen flexibel angepasst. Auch im Bereich der Übersetzung ergab sich ein grundlegender Wandel: Statt aufwendiger Export- und Importprozesse kam das integrierte Übersetzungsmanagement zum Einsatz. Darüber hinaus mussten sich die Autoren an explizite Publikationsprozesse gewöhnen, die zuvor im SAP-System weitgehend implizit abgebildet waren. Inhalte durchlaufen nun klar definierte Schritte von der Erstellung bis zur Auslieferung.
Trotz dieser Umstellung zeigte sich schnell ein deutlicher Effekt. Innerhalb kurzer Zeit entstand ein hochgradig wiederverwendbarer, variantengesteuerter Content-Bestand auf DITA-Basis. Die Autorinnen und Autoren adaptierten die neuen Arbeitsweisen und entwickelten sogar ein hohes Maß an Akzeptanz und Engagement im Umgang mit den neuen Möglichkeiten.
Weiterführendes Projektbeispiel:
Dass dieser Wandel nicht nur für CPQ-nahe Angebotsprozesse relevant ist, zeigt auch ein weiteres PANTOPIX-Projekt. Unsere Case Study beschreibt die zukunftssichere Produktkommunikation mit DITA, CCMS und Content Delivery Portal. Auch dort stehen strukturierte Inhalte, Metadaten und eine skalierbare Content Supply Chain im Mittelpunkt.
Fazit
Die wichtigsten Erkenntnisse aus dem Projekt lassen sich klar zusammenfassen. DITA erweist sich als zentraler Enabler, weil ohne schnelle und strukturierte Content-Erstellung das gesamte System inhaltsleer bleibt. Ebenso entscheidend ist die frühzeitige Einbindung der Autorinnen und Autoren, da die beste Architektur wirkungslos bleibt, wenn sie nicht genutzt wird. Schulung spielt dabei eine zentrale Rolle, um nicht nur Werkzeuge, sondern auch Prozesse zu verstehen. Schließlich zeigt sich, dass Knowledge-Graph-Ansätze oft über ihren ursprünglichen Zweck hinaus wirken und Verbesserungen in Bereichen ermöglichen, die zu Beginn nicht im Fokus standen.
In der Gesamtbetrachtung verschiebt sich die Rolle von Content grundlegend. Er wird zur zentralen Infrastruktur eines digitalen Angebotsprozesses. DITA, Knowledge Graphen und CPQ-Systeme sind in diesem Kontext keine isolierten Technologien, sondern Bausteine einer gemeinsamen Architektur. Ihr Zusammenspiel ermöglicht es, Content zu industrialisieren und damit eine große Skalierungsbarriere in variantengetriebenen Geschäftsmodellen systematisch zu überwinden.
Der Artikel wurde über das Center for Information-Development Management (CIDM) veröffentlicht.

Karsten Schrempp
Managing Director | PANTOPIX
Wir informieren Sie gerne regelmäßig über neue Artikel, Videos oder Podcast-Folgen.

Knowledge
Erfahren Sie mehr über das Vernetzen von Informationen