
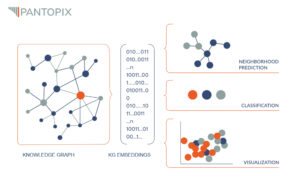
Knowledge Graph Embeddings
Unterschiedliche Datenquellen in einer Wissensdatenbank zusammenzuführen und die semantische Repräsentation der dort enthaltenen Informationen können die Technische Kommunikation erheblich erleichtern. Der Aufbau einer Wissensdatenbank mithilfe semantischer Wissensgraphen bietet zahlreiche Vorteile, darunter die wichtige Möglichkeit, den Wissensgraphen kontinuierlich zu erweitern. Eine Methode zur Erweiterung des Wissens besteht in der Anwendung von Einbettungen für Wissensgraphen (Knowledge Graph Embeddings).

Docs-as-Code: Automatisierte Software Dokumentation
Die Welt der Softwareentwicklung verändert sich ständig, und mit ihr auch die Art und Weise, wie wir Software dokumentieren. Eine innovative Methode, die in den letzten Jahren an Popularität gewonnen hat, ist “Docs-as-Code” oder Dokumentation als Code. In diesem Artikel werden wir uns mit dieser spannenden Entwicklung auseinandersetzen und den Anwendungsbereich in der Technischen Dokumentation genauer beleuchten.
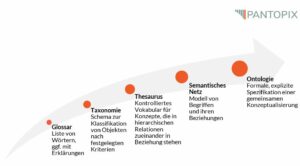
Bedeutung von Semantik in der Technischen Kommunikation
Heute wird immer häufiger über Semantik gesprochen, insbesondere im Zusammenhang mit Begriffen wie “Semantisches Web” oder “Semantisches Wissensmanagement”. Doch was genau bedeutet Semantik und wie relevant ist sie für die Technische Dokumentation?
